Dual process: new paradigm for building chatbot
ChatGPT has demonstrated that one can build a chatbot capable of generating sensible responses to almost any question based on the collective knowledge encoded in the web dump on which it was trained. Recently, prompt engineering, together with retrieval-augmented generation, has emerged as a new way for businesses to create chatbots that expose business-specific information found in past conversations and existing documents, without the need to write a single line of conversation flow code.
Syetem 1 vs System 2
Prompt engineering with LLM is not enough
Using natural language to program or control the every aspect of LLMs’ output, prompt engineering is democratizing and greatly reducing the cost of the chatbot development. As LLMs become more powerful, this new development paradigm is likely to become an increasingly important. However, it lacks the precise control sometimes required by business use cases. Furthermore, when it failed to generate desired output, the ways to fix it are limited:
- Adjust prompt. Exact behavior of the LLMs on a given input under a prompt can not be predicted, you can only found it out by trying it. So different prompt might help.
- Fix datasets, by adding the text that is easy for LLMs to pick up in order to address some questions.
- Refine orchestration, by selecting better documents as context.
- Improve alignment by tuning using supervised fine tuning (SFT) or Reinforcement Learning from Human Preferences (RLHF).
- Add domain knowledge by continual pre-training with addition in-domain text.
Clearly, none of these fixes can make prompt engineering as dependable as the old software engineering. So is it possible to have the best of both prompt engineering and software engineering?
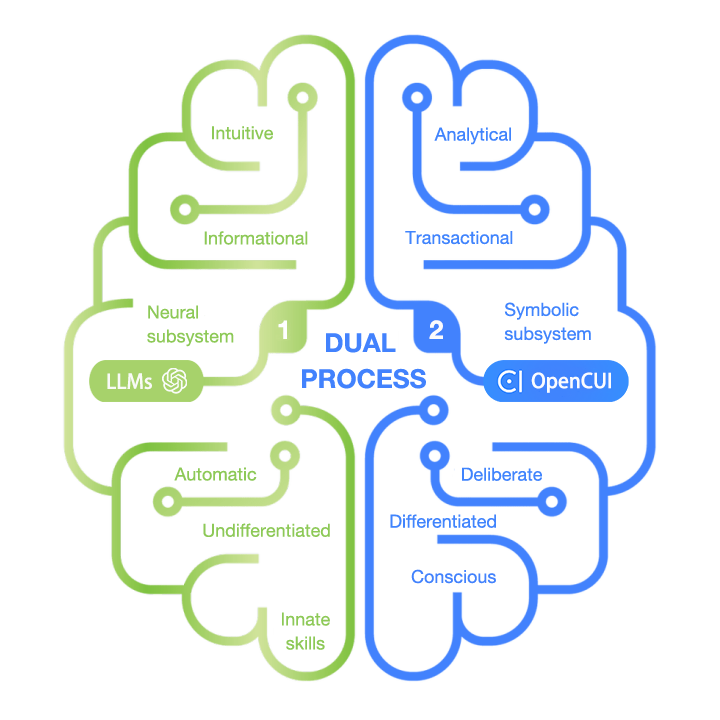
Dual Process
In his popular book “Thinking, Fast and Slow,” Nobel laureate Daniel Kahneman revealed that the human brain actually has two distinct systems that work in tandem. System 1 provides quick responses for mundane tasks based on intuition, while System 2 steps in for tasks with higher impact that require more effortful and analytical thinking. This dual-process framework enables us to handle a wide range of cognitive tasks efficiently, make quick judgments when appropriate, and engage in more reflective thinking when faced with complex or novel situations.
The brain possesses limited cognitive power, and allocating it efficiently with a dual-process system is crucial for survival. Businesses have to navigate even more complexity with limited resources. We argue that the future chatbots that businesses build should also operate as a dual-process system. Therefore, they should be developed with both paradigms together.
Software built with traditional method is System 2
Until very recently, software was written in languages such as Python, C++, etc., using explicit instructions that dictate how the input is processed to produce the desired output. This requires developers to possess a detailed understanding of the problem domain and follow a deliberate process, including requirement analysis, design, implementation, testing, and deployment. However, this approach can be expensive.
The solutions, created by software engineers or developers, are often interpretable and transparent since they operate based on explicit rules and logical reasoning. Therefore, it is reasonable to claim that such solutions behave like a System 2, as every step they take is the result of the deliberation of their human expert developer.
LLMs are System 1
However, many real-world tasks, such as determining whether an input image contains a car or not, are impossible to solve with step-by-step solutions. This is where machine learning, particularly neural network-based approaches, comes into play.
The neural network’s behavior and functionality, instead of being explicitly programmed by developers, is defined by weights of its connections, and is learned from data for its predefined architecture. This learning process, also known as training, finds optimal weight values that minimize the difference between predicted and actual outputs for a given set of input data.
The way neural networks process input is very similar to System 1. They can process information in parallel, quickly analyze patterns in data, and make rapid predictions or classifications based on the learned patterns. Similar to System 1, it is often difficult to explain the exact reasoning for these responses.
Chatbots are software with conversational user interface.
To decide which approach to use when developing a chatbot, it is useful to understand business requirements from the following two perspectives:
Informational vs transactional. Historically, chatbots have provided users with information without taking any actions. However, with the emergence of copilot chatbots, there is an expectation for them to perform actions on behalf of users. This requires the chatbot to interact with backend systems in the service layer.
Differentiated vs undifferentiated solutions. Businesses need to differentiate in order to better serve their market segment. Figuring out what and how to differentiate from others requires deliberation and systematic experimentation. Businesses only differentiate when they need to. It is common for businesses to reuse existing solutions as much as possible to save costs.
When to pick software engineering
The benefit of using software 1.0 to build chatbot is the control it offers to business. Under the von Neumann architecture, the semantic of every instruction is deterministic, so chatbot built this way always generate exact response as designed. This deterministic control, however, comes with a steep cost.
For every functionality you provide to user through CUI, you need to design API schema first. The APIs need to be implemented and then deployed as service before frontend can expose these functionality to your user. The development of these deterministic solutions thus requires human experts in both business domain and software development stack, and it can be costly and will take a long time.
Software 1.0 development is best suited when the chatbot needs to take action or call functions via service APIs for the user. The conversational interactions required for taking action are typically more complex, often necessitating additional conversation flows such as confirmation and recommendations. To deliver a seamless conversational experience, these conversation flows need to interact with the production system in a controlled way. Developing chatbots in software 1.0 is also useful when businesses need to differentiate themselves, which generally involves experimenting with novel solution.
When to pick prompt engineering with LLMs
Neural networks has been used as component for chatbot, for example dialog understanding, in software 1.0 for a long time. But recently, they are used to build chatbot end to end for some use cases. In particular, Large Language Models (LLMs) are trained on vast amounts of text data to learn the patterns, structures, and semantics of language, as well as the common sense knowledge encoded in that data. An instruction-tuned LLM, such as ChatGPT, can assist users in various ways within a conversational user interface.
While it is possible to use prompts to solve many problems with LLMs, the solutions obtained under these zero-shot learning settings are only effective if the domain has a decent representation in the training set. No machine learning solution can perform well in new domains. However, manual labeling of data is never an efficient method for “teaching” a system the desired behavior and can be prohibitively expensive. But when there is an abundance of labeled examples available as a byproduct of human activities, training neural networks to solve problems becomes a sensible approach.
By combines the strengths of language generation and information retrieval, the retrieval augmented generation using LLMs has shown some promise in serving informational request using just existing document, knowledge base, etc without extra effort. It is also a good idea to build chatbot based on LLM for the undifferentiated services, when there are enough public domain examples already available.
Chatbots should be dual-process system
Both software engineering and prompt engineering with LLMs can be effective for building chatbots, but for different use cases. Instead of sticking to one approach, it is beneficial to pick the right tool for each use case. Therefore, the future of chatbots/copilots will very likely be a dual-process system, with a symbolic subsystem or System 2 built with traditional software engineering responsible for differentiated or transactional services, and a neural subsystem or System 1 based on LLMs responsible for undifferentiated or informational services.
But how do two completely different subsystems work together? One way to make this dual-process approach work is to have two versions of the chatbot running in tandem. User input will be fed into both versions, also the response generated by one system will be feed into another system, so that both systems can have a complete conversation history. Of course, we need to figure out a way to model the capabilities of at least one system, so that we can dispatch the user input to the right subsystem.
Parting words
Where there is an abundance of data, such as historical manual records, prompt engineering with LLMs can be used to create a System 1 chatbot to serve your users with minimal effort and cost. However, when data is not yet available, or when you want to differentiate from common practices, the software engineering approach will still be the way to go. Using both approaches to building chatbots allows you to create a great conversational experience in a cost-effective fashion while handling every possible use case, maximizing the return on your investment.