Chatbot in 3 layers
Built on the principle of separation of concerns, modern GUI library or frameworks, such as React and Vue, divides application into model, view and controller, with each specific responsibility taken care of by different group of people. These framework has made it more affordable for businesses to build functional web and mobile applications. According to Gartner, chatbot deployment costs can range from $50,000 to a few million U.S. dollars, thus is substantially more expensive. It is not surprising that chatbots are generally built by these deep pocketed business like Bank of America, for example. Is it possible to adopt the same idea to make chatbot development more cost-effective?
Separation of Concerns
The principle of separation of concerns allows for efficient and effective software development by dividing the software into distinct horizontal layers, each addressing a separate concern. Each concern is governed by a set of cohesive principles and is applicable across different domains.
Furthermore, layers are interact with other layer through predefined interfaces between different concerns, so work from different teams can fit together to deliver the desired functionality. In modern web application development, it is common to divide the system into back-end for business logic, front-end for interaction logic, and UI component for appearance. The interface between back-end and front-end can be described through OpenAPI, and the interface between interaction logic and appearance can be defined using JavaScript and frameworks such as antd for React. With each concern handled by people with corresponding specialization, we can greatly increase the both the quality and productivity of the work.
Chatbot in 3 layers
Generally, businesses build chatbot to provide their services through conversational user interface. As more and more business use chatbot as way to directly communicate with their users, regardless which channel they come from and what language they speak, it becomes clear that chatbot should be modeled in the 3 layers as follows.
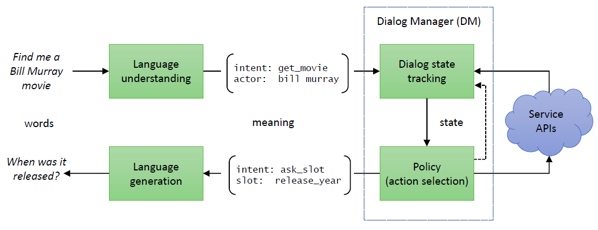
Service schema
Services are typically implemented in the back-end, and exposed by a set of API functions. These functions can be defined by some API scheme, mainly details the function signature, including data types for their parameters and returns. While there are new APIs specifically designed because of chatbots, all service APIs can be shared between different frontends: including web and mobile apps. So one can safely assume the back-end service is already available, or it can be taken care of as a separate concern.
Interaction logic
In case user does not provide all the information in one go, or users change their mind in the middle of conversion, chatbot need to conduct conversation to gather required information to invoke service API. The interaction logic is typically language-independent to ensure a consistent user experience regardless of the language used to interact with the chatbot.
Naturally, the interaction logic layer interact with back-end through well-defined APIs. For example, when prompting movie goers for their movie preference, it is a good idea to provide candidates list that is still available for the day, or lets user know if their choice of items ran out, all by making use of service APIs.
The functionalities of an API are already described using a language like OpenAPI. The challenge is how to invoke these functions naturally using conversational interaction logic. Most CUI platforms only support intent with entity slots, which makes it difficult to interact with functions that have parameters of composite types, list-contained types, or even polymorphic types. By supporting a modern type system within conversational interaction logic, it becomes easier to interact with these functions and promotes the reuse of conversational behaviors.
Language perception
This layer is used to convert user utterances into structured representation of semantics, or frames, using natural language understanding (NLU), and generate natural text for given semantic frame using natural language generation (NLG). We need automatic speech recognition (ASR) and text to speech (TTS) to convert sound wave and back if we want to communicate with user via voice.
While recent progress in deep neural networks has made these problems much easier, there are still couple of design decisions that can greatly impact the developer experiences. The semantic space capture refers to the way in which we understand user utterances. There are two main approaches: literal meaning, which involves understanding the utterance without any context, and implied meaning, which involves interpreting the utterance based on a particular context. For example: “I have a meeting in Beijing on Tuesday morning.” can be interpreted into “{destination=beijing, time < Tuesday}” by the travel agent when he hears this from his client. Clearly, use implied meaning as semantic space can reduce the effort level down the road. How do chatbot developer develop and hot fix the understanding problem? Traditionally, chatbot developer need to train a separate ML model for each chatbot, and fix the understanding under this paradigm can be extremely time-consuming. With recent advance in zero-shot learning based on large language model, it is now possible that chatbot developer can develop and hot fix understanding module without knowing how to training a machine learning model.
Summary
The three-layered approach for building GUI applications has been successful and widely adopted, including on desktop, web, and mobile. We believe this same approach can be applied to building chatbots, specifically using our 3-layered CUI framework OpenCUI. OpenCUI focused on using zero-shot learning towards implied meaning, and entirely do away with training, our dogfooding have found it to be cost-effective in developing CUI’s. Give it a try today.